Édition multiformat au musée du Louvre
Collectif
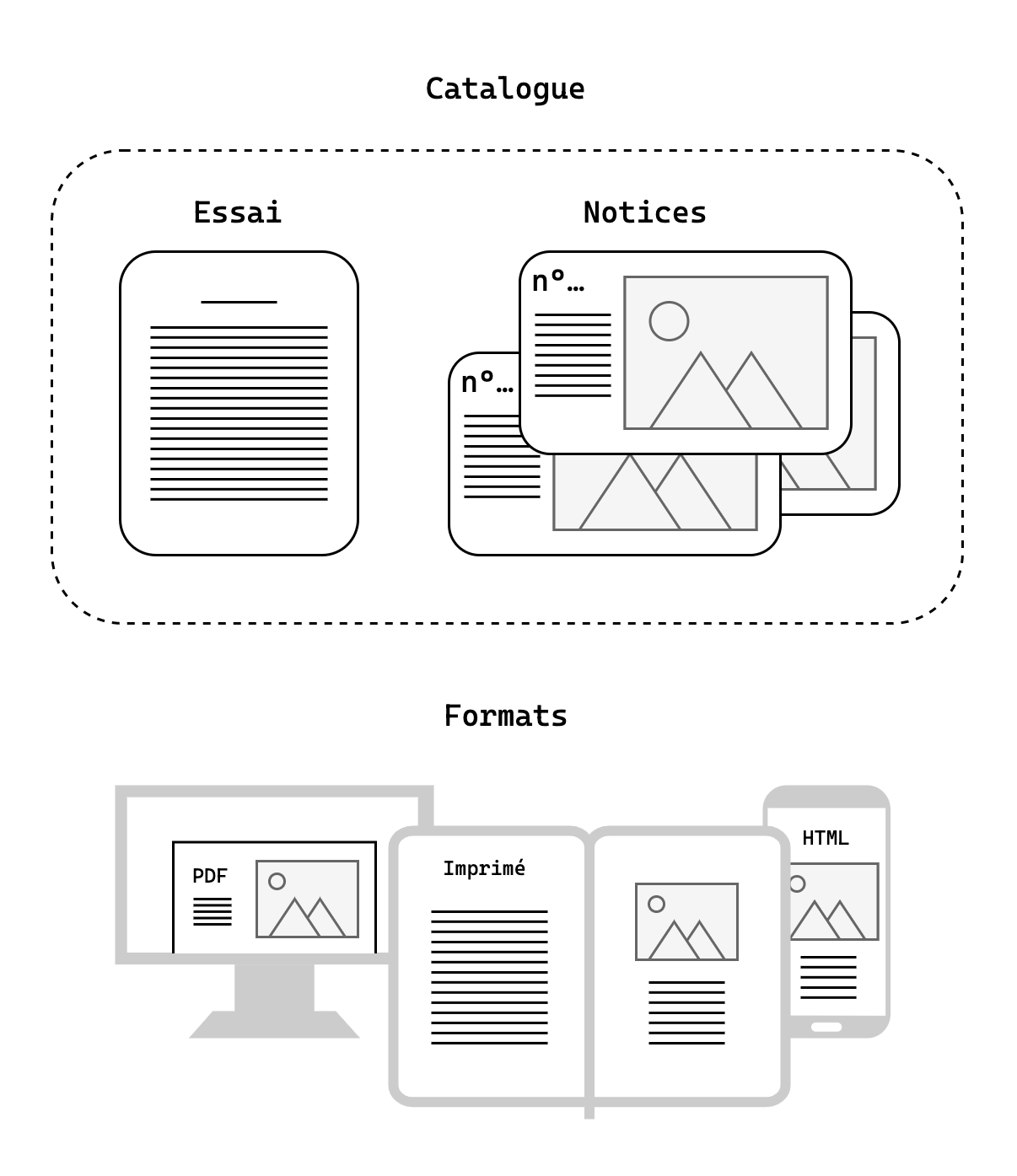
Il faut d’abord expliquer ce qu’est un catalogue de collection : un document qui décrit tout ou partie des collections d’un musée. Il existe une certaine plasticité du terme « catalogue », qui peut désigner des objets très différents. Pour le catalogue Van Dyck, le projet a été résolument pensé comme un livre : il ne s’agissait pas seulement d’exposer une collection mais aussi de présenter le travail d’un chercheur, donc de faire une publication citable. On y retrouve un essai introductif, puis une succession de notices qui décrivent chacune une œuvre. Conceptuellement, ce format éditorial évoque une base de données, dont chaque unité est constituée par un numéro de catalogue, une image, des métadonnées et un texte descriptif.
Ce livre a ceci de particulier qu’il est multiformat : il existe une version papier mais aussi des versions numériques. Ces dernières sont accessibles gratuitement. L’ambition était de combiner les avantages du papier et du numérique pour réaliser une édition scientifique de qualité (pérenne, bien référencée) avec une plus grande diffusion.
Pour préciser ce qu’on entend ici par multiformat, il s’agit d’un principe théorisé par les bibliothécaires sous la forme du modèle FRBR : une œuvre est réalisée par une expression, qui est concrétisée par une manifestation, qui se décline en exemplaires. Dit autrement, un même contenu peut prendre des formes différentes : par exemple, un livre édité au format poche n’a pas les mêmes dimensions ni la même mise en page que dans sa première édition. Aujourd’hui, des livres sont publiés simultanément dans différents formats imprimés mais aussi différents formats pour écrans (ordinateur, tablette, téléphone, liseuse).
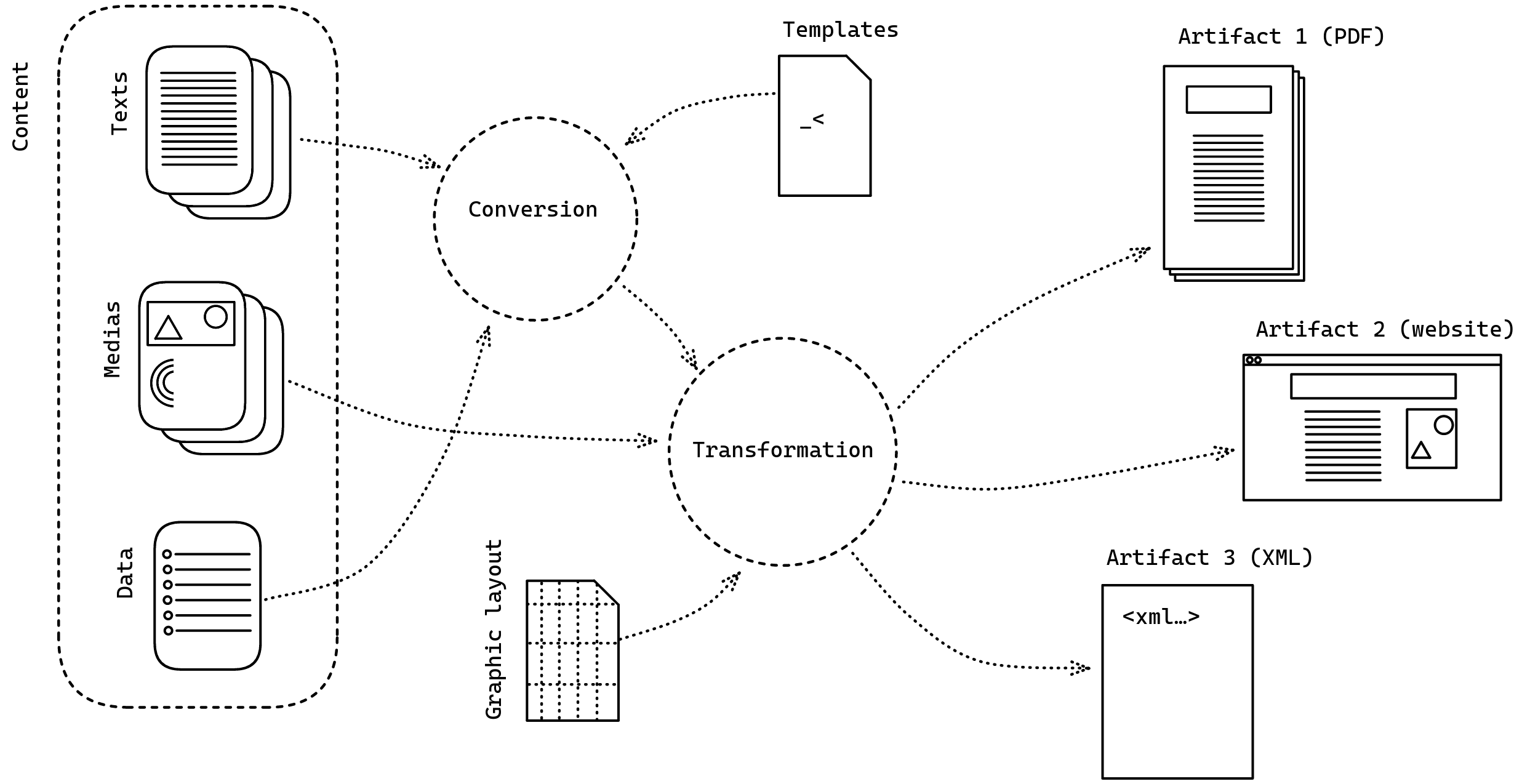
Une nouveauté apportée par l’informatique au multiformat est le single source publishing : une technique qui consiste à fabriquer différents formats à partir d’une seule expression. Pas de duplication du contenu pour chaque format : on travaille avec un seul fichier (ou jeu de fichiers). Mais il faut bien noter que l’opération n’a rien de magique. D’abord, chaque média propose des usages différents de l’information : les formats numériques peuvent inclure des éléments et fonctionnalités qu’on ne retrouve pas dans les formats papiers (comme un moteur de recherche, la possibilité d’agrandir les images) et vice-versa. Donc, même si le contenu citable est exactement le même d’un format à l’autre, l’homothétie entre les formats ne peut pas être parfaite. Et ensuite, pour préparer ces différentes possibilités médiatiques, il faut intervenir sur le fichier « source » : pour reprendre la terminologie FRBR, créer des manifestations différentes d’une même œuvre nécessite d’adapter l’expression de cette œuvre. Ces adaptations de la forme mais aussi du contenu doivent donc souvent être pensées projet par projet.
Faire un livre multiformat n’est pas une évidence pour un éditeur de livres d’art. Mais surtout, fabriquer un catalogue de collection multiformat en single source publishing représente un défi technique, car il n’existe pas d’outil dédié. Les outils de publication scientifiques existants sont pensés pour des formats éditoriaux (revues, livres classiques) trop différents du catalogue raisonné ; par ailleurs, ces outils manquent de fonctionnalités adaptées à l’histoire de l’art (notamment pour la manipulation des images et des métadonnées).
Le Louvre a donc fait appel à l’expertise de Julien Taquet, qui travaille pour Coko, une fondation à but non lucratif qui fabrique des outils pour l’édition (comme Paged.js). Objectif : créer une chaîne éditoriale numérique sur mesure à partir de Flax, un outil développé par Coko sur la base du générateur de site statique Eleventy. Le mot chaîne désigne ici un logiciel (ou un ensemble de logiciels) qui englobe les différentes étapes de fabrication d’une publication. Le rôle de la chaîne est de faciliter la communication entre humains sur l’objet en train d’être fabriqué. Idéalement, elle s’adapte à la manière dont ces humains travaillent, avec des choix pragmatiques : par exemple, si la majorité des auteurs écrivent dans Microsoft Word, alors une chaîne doit être compatible avec cet outil et le format docx, qu’elle doit pouvoir transformer en d’autres formats. Une chaîne est souvent composite, accueillant de façon modulaire de petits utilitaires adaptés à des besoins particuliers (par exemple la fabrication d’un index).
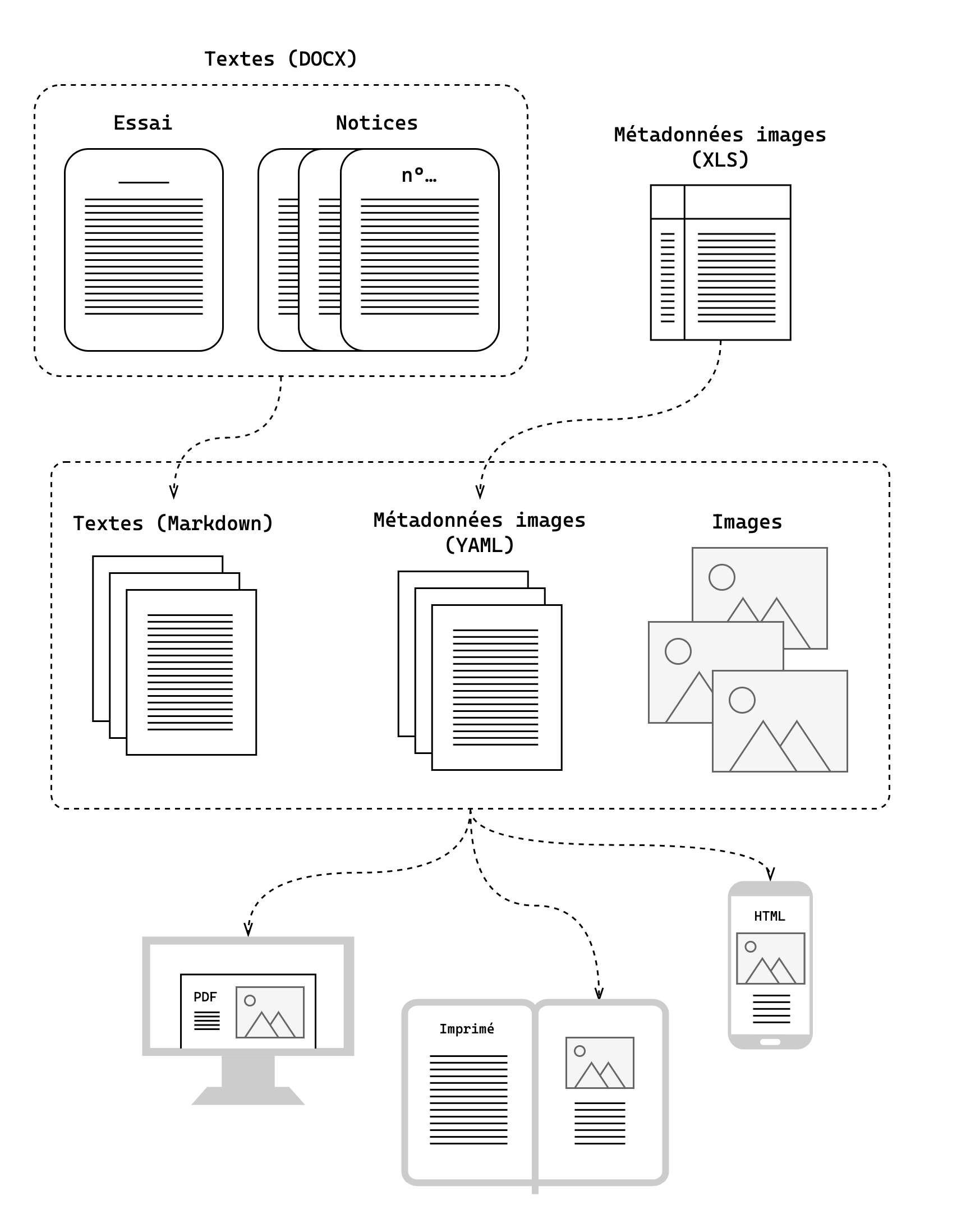
Décrivons la chaîne réalisée pour le catalogue Van Dyck (les textes étant déjà finalisés par l’auteur et l’éditrice, il s’agit uniquement d’un environnement d’édition) :
-
L’équipe a d’abord défini le « modèle de données » du livre : le langage commun utilisé par les humains pour décrire les contenus (unité documentaire, figure, métadonnée…) afin que les machines puissent interpréter ces contenus.
-
Sur cette base, des styles sont créés dans le logiciel de traitement de texte et appliqués aux contenus.
-
Les fichiers docx ainsi structurés sont ensuite convertis au format texte, afin de gérer la collaboration et les versions via git. L’utilisation d’un langage de balisage léger (Markdown) et d’une interface web (GitLab) permet de faciliter l’intervention de l’éditrice sur les textes après conversion. Pour structurer de manière plus fine le contenu (par exemple pour indiquer que les premiers paragraphes d’une notice ont une signification spécifique), la chaîne utilise une variante de Markdown permettant d’inclure du balisage sémantique via des attributs. Et pour gérer les objets complexes qui varient d’un format à l’autre (par exemple les figures), la chaîne utilise des expressions dans un langage de templating (Nunjucks), qui sont transformées différemment suivant le format de sortie.
-
L’iconographie fait l’objet d’un traitement similaire à celui des textes mais avec une conversion depuis un tableur vers des fichiers texte au format YAML.
-
Tous ces fichiers sont utilisés par la chaîne pour fabriquer les différents formats d’export, en intégrant les styles définis d’après le brief graphique.
Durant cette dernière étape, la chaîne permet également de fabriquer un rendu HTML qui simule l’apparence d’un PDF affiché en double page, dans le navigateur. Il faut s’arrêter un instant sur ce rendu HTML, qui n’est ni un format d’origine, ni un format de destination : ce n’est pas la version HTML finale du livre mais une simulation de sa version PDF. C’est un format de travail, intermédiaire, qui permet de repérer les endroits nécessitant des ajustements complexes. La chaîne comporte d’ailleurs un système en deux temps pour l’application des styles : une première passe pour appliquer les styles de base, puis une seconde passe pour ajouter éventuellement des styles correspondant à des modifications uniques sur des éléments précis, décidées après avoir vu le rendu HTML. On est ici en face d’un processus profondément séquentiel et itératif. Et si la chaîne met en œuvre une séparation stricte entre contenu et mise en forme, cela ne signifie pas une négation ou un impensé de la forme, bien au contraire.
Nicolas utilise l’expression html-to-print pour souligner le rôle que joue HTML comme format de travail et pour prendre ses distances vis-à-vis de l’expression web-to-print, qui tend selon lui à devenir une notion marketing : la promesse un peu réductrice d’une transformation automatique de la page web en PDF.

L’esprit du livre papier a fortement influencé le design de la version web. La « page d’accueil » se veut une page de « couverture » : elle en reproduit le design avec une image de fond, le titre, le nom de l’auteur, le logo de l’éditeur, une bande noire sur le côté qui rappelle le dos du livre (et qui permet de révéler le sommaire). Dans les « pages intérieures », contenus textuels et images sont présentés en vis-à-vis, avec de grandes images affichées en bord à bord, comme les doubles pages correspondantes dans la version papier. Les codes de l’imprimé guident également la navigation dans les contenus : un « fil d’Ariane » reproduit ainsi le design de feuilletage du livre, d’une page à une autre ; certains éléments (images, notes, sommaire) sont persistants, ou bien défilent de manière finement réglée, pour ne pas perdre le lecteur. On voit ici que l’attachement au livre n’est pas rétrograde mais le socle sur lequel viennent s’appuyer des choix de conception pertinents. D’ailleurs, il est possible de citer de manière identique toutes les versions, car elles incluent toutes une numérotation par texte, ou par notice, et par paragraphe : un exemple que beaucoup d’éditeurs scientifiques feraient bien de noter.
Point typo ❧ Le livre utilise deux polices de caractères pour distinguer différents types d’information : Roboto (utilisée dans la charte graphique du Louvre) pour les textes techniques et les petits caractères ; EB Garamond (police riche en caractères et open source, donc adaptée aux besoins d’une édition scientifique complexe), plus littéraire, pour le reste du texte.
Fait rare, souligné par Julien : malgré le défi technique que représentait le développement de la chaîne, très peu de concessions ont été faites par rapport aux intentions éditoriales et graphiques. Pour résoudre des questions de typographie et de mise en page très fines, les outils ont parfois été poussés dans leurs retranchements. Ceci reflète autant l’exigence des personnes impliquées que la conscience de travailler sur un projet exceptionnel, au sens statistique… on y revient dans la partie Discussion ci-dessous.
Discussion
Question : Comment chaque personne intervenait-elle sur la chaîne, via quelles interfaces ?
Réponse : Chacun (iconographe, auteur, éditrice, développeur, graphiste) a pu utiliser son outil de prédilection car les choix de formats permettaient l’interopérabilité des outils. Donc suivant les rôles : traitement de texte, tableur, éditeur de texte, éditeur de code (et différents éditeurs d’ailleurs).
Un élément intéressant, c’est que les différences de besoins entre métiers induisent des adaptations de la chaîne : par exemple, durant le stylage, quand on fait une modification on veut voir tout de suite le résultat, car on a besoin d’itérer très rapidement ; donc contrairement aux modifications des textes, ici on ne lance pas une recompilation complète mais on écrase juste la CSS modifiée et on visualise immédiatement le résultat.
Les corrections de maquette et les relectures d’épreuves se sont faites de manière traditionnelle, avec des annotations sur PDF imprimé. La notion de « jeux d’épreuves » successifs est fondamentale : elle permet de maintenir le contrôle et une qualité maximale de la relecture et de l’intégration des corrections.
« À chaque fois que tu tournes une page,
y’a une nouvelle difficulté ! »(Nicolas)
Q : Quelles étaient les adaptations les plus difficiles par rapport à ce que vous connaissiez déjà ?
R : Il y a des choses complexes mais anticipées. Par exemple, le calibrage des images, les corrections colorimétriques, font partie du processus habituel au Louvre, qui implique photograveur, conservateur et éditrice. Il y a aussi des choses auxquelles on s’adapte sans difficulté : l’impression à la demande, par exemple, s’est révélée satisfaisante. Et puis il y a des éléments qui ont nécessité une attention toute particulière et minutieuse, comme la fabrication de l’index.
La vraie difficulté n’est pas technique mais réside dans la compréhension des attentes des uns et des autres, ce qui est nécessaire pour que la prise de décision collective marche. Il faut établir une vision commune, puis itérer.
Q : Le coût global de ce genre de réalisation le limite-t-il pour le moment à des éditeurs institutionnels ?
R : Les ouvrages publiés par le Louvre sont très souvent onéreux, de par le volume et la nature des contenus (textes, iconographie, traductions, index…) et par l’ensemble des savoir-faire à mobiliser pour l’édition d’un livre d’art : les coûts de production de tels ouvrages excèdent de loin ceux qu’on connaît dans l’édition scientifique classique. En outre, le Louvre publie selon le système de la coédition : un cadre juridique qui permet la mutualisation des coûts entre le secteur public et le secteur privé. Le catalogue Van Dyck a coûté aussi cher qu’un très gros catalogue d’exposition, soit plus cher qu’un catalogue de collection classique – le prix des compétences nécessaires pour réaliser du multiformat avec le même niveau d’exigence pour chaque format – mais sans partage des coûts. Enfin, là où le catalogue d’exposition voit sa visibilité et ses ventes portées par le succès de l’exposition, et en cela l’institution publique soutient le secteur du livre d’art, le catalogue scientifique de collection, lui, reste un secteur beaucoup plus marginal.
La chaîne est réutilisable, c’est le but du travail chez Coko. Mais le coût des compétences est incompressible. On peut réutiliser les outils et faire plus simple. Il faut saluer le rôle d’institutions comme le Louvre dans la réalisation de tels projets, rares.
Un deuxième livre est en préparation : un catalogue de la collection des stèles puniques conservées au Louvre. Avec 1400 objets, le défi sera celui du passage à l’échelle. Le modèle de données sera forcément différent, et le tableur jouera un rôle accru. Nicolas l’annonce : ce sera l’avènement de l’Excel-to-print !
Compte-rendu réalisé par Arthur Perret avec l'aide d'Antoine Fauchié (prise de notes) et de Camille Sourisse (relecture).